
O cross-selling é uma estratégia que pode otimizar as vendas e a satisfação dos clientes. Por trás dos panos, usamos regras de associação para calcular quais são as sugestões a serem feitas para que possamos atingir essa otimização.
Neste artigo entramos no detalhe do que são regras de associação, como elas são estruturadas através de antecedentes e consequentes e como mensurar a força dessas associações através do support, confidence e lift.
No nosso último artigo discutimos os benefícios e a vantagem competitiva que é utilizar o cross-selling para inferência do mix de produtos a serem ofertados para os clientes de modo a otimizar as vendas. O cross-selling usa como base as regras de associação, de modo a detectar a relação entre os dados. Neste artigo, vamos entender, no detalhe, o que são as regras de associação e como elas funcionam.
Regras de associação são, basicamente, afirmações do tipo “se-então” que ajudam a mostrar a probabilidade de relacionamentos entre dados de grandes bases de dados. Em ciência de dados, essas regras de associação são usadas para encontrar correlações e co-ocorrências entre dados e o ato de usar essas regras de associação normalmente é chamado de “mineração de regras de associação”. Vale ressaltar que as regras de associação não trazem novo significado a um item da base de dados por si só, mas sim encontram relacionamento entre itens.
Resumindo de uma forma simples, a mineração de regras de associação usa modelos de Machine Learning para analisar padrões em uma base de dados, encontrando assim as associações “se-então”, que foram citadas anteriormente. Uma regra de associação é composta por:
• Antecedente: item ou lista de itens encontrados nos dados, é o “se” da relação “se-então”
• Consequente: é o item ou lista de itens encontrados em combinação com o antecedente. É o “então” da relação “se-então”.
Para avaliar a força dessas regras de associação são usados diversos critérios sendo que os mais relevantes são o support (suporte) e confidence (confiança). Support é um critério que indica quão frequente aqueles itens são encontrados nos dados. Confidence indica o número de vezes que a relação “se-então” se confirma verdadeira. Uma outra métrica, chamada lift (elevação), é usada para compreender se o valor de confidence de fato mostra uma relação “se-então” válida.
Vamos para um exemplo prático, de modo a elucidar melhor os conceitos citados. Estamos estudando uma base de dados de vendas de um pequeno mercado e buscamos encontrar regras de associação entre os produtos vendidos. Vamos pressupor que o nosso conjunto de itens encontrados em uma dada regra de associação, ou seja, a lista de itens que compõe tanto o antecedente como o consequente, é {Pão, Ovo, Leite} e que a relação encontrada é {Pão, Ovo} → {Leite}, ou seja, os itens Pão e Ovo compõe o antecedente e o Leite compõe o consequente.
Como os critérios citados anteriormente nos auxiliam a entender a força da relação entre esses produtos? O support nos indica quais regras de associação são relevantes para uma análise mais profunda, indicando a porcentagem de aparições daquela regra de associação no total das transações registradas na base de dados. Quanto maior o valor calculado do support, maior a relevância daquela regra de associação na base de dados. O suporte neste exemplo seria calculado da seguinte forma:
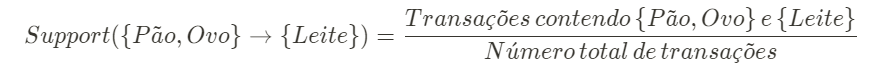
Já a confidence nos indica a chance da ocorrência do consequente, dada a ocorrência do antecedente, sendo que um valor alto de confidence indica grandes chances de co-ocorrência dos itens. Ou seja, dado que o cliente comprou Pão e Ovo, qual a chance de que ele também tenha comprado Leite? O cálculo, neste exemplo é feito como segue:

O problema de usar apenas o valor de confidence é que itens muito comprados podem gerar altos valores, mesmo que a oferta conjunta desses itens não traga benefício algum. Por exemplo, usando novamente o leite, que é um item muito comprado, pode ser que o valor de confidence da relação {Shampoo} → {Leite} seja muito alto, dado que apesar de shampoo e leite não terem grande similaridade, leite é comprado por quase todos os consumidores e, consequentemente, quem compra shampoo tem grandes chances de comprar leite. Sabemos intuitivamente que essa relação não faz muito sentido, apesar do alto valor de confidence. Para superar esse ponto, usamos o valor de lift.
O lift leva em consideração o número de transações contendo o consequente, de modo que indica a “elevação” que o antecedente provê à confiança de possuir o consequente na transação. Esse valor, no exemplo, é calculado por:
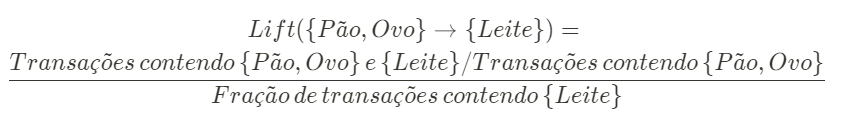
Um lift menor do que um indica que possuir Pão e Ovo na transação não aumenta as chances de ocorrência de Leite, mesmo que o valor de confidence seja alto. Lift maior que um confirma a grande associação entre os dados.
Tendo entendido o significado desses parâmetros, podemos então calcular esses valores para a nossa base de dados (sendo que existem diversos algoritmos que foram criados pensados nessa tarefa), de modo a entender as regras de associação mais fortes e, com isso, é possível tomar diversas medidas que, no caso do exemplo de um mercado, visam otimizar a venda conjunta dos produtos e, com isso, maximizar o valor das vendas.
Guilherme Busato Vecchi
Analista de dados na Zeta
[1] https://www.techtarget.com/searchbusinessanalytics/definition/association-rules-in-data-mining#:~:text=Association rules are “if-then,in various types of databases.
[2] https://towardsdatascience.com/association-rules-2-aa9a77241654
[3] https://towardsdatascience.com/im-a-data-scientist-why-should-i-use-the-cloud-b896ded55bb9
[4] https://medium.com/analytics-vidhya/an-intro-to-cloud-computing-for-data-scientists-and-data-engineers-96d85b4852de








